
🦁멋쟁이사자처럼 백엔드 부트캠프 13기 🦁
TIL 회고 - [75]일차
🚀75일차에는 도커 컨테이너의 모니터링 관리 도구인 프로메테우스와 그라파나에 대해 배울 수 있었다.
학습 목표 : 프로메테우스와 그라파나 모두 컨테이너로 실행하여 프로젝트의 요청에 대해 변화하는 것을 모니터링 가능
학습 과정 : 회고를 통해 작성
프로메테우스 / 그라파나 모니터링
Spring Boot Actuator
- 애플리케이션의 상태 (Health, Metrics, Info 등)를 확인하고 관리할 수 있도록 도와주는 강력한 모니터링 관리 도구
- Spring Boot를 사용하면 간단한 설정만으로 다양한 Actuator endpoint를 사용하고 커스터마이징 가능
프로메테우스
- ex. 매 5초마다 웹 서버 컨테이너의 CPU 사용률은 15%", "데이터베이스 컨테이너의 메모리 사용량은 5GB
같은 정보를 기록 - ➡️시스템이나 애플리케이션의 메트릭 데이터를 수집하고 시계열 형태로 저장하는 모니터링 시스템
그라파나
- ex. 프로메테우스가 기록한
"웹 서버 컨테이너의 CPU 사용률" 데이터를 가져와서 지난 1시간 동안의 CPU 사용률 변화를 선 그래프로 보여줌 - 이를 통해 매니저는 웹 서버의 CPU 사용량이 안정적인지 쉽게 체크 가능
- ➡️프로메테우스와 같은 데이터 소스에 저장된 데이터를 가져와 시각화하여 보여주는 데이터 시각화 도구
✅두 도구를 함께 사용하여 도커 환경에서 실행되는 애플리케이션과 컨테이너들의 상태를
효과적으로 모니터링하고 분석하여 시스템의 안정성과 성능을 높일 수 있음
프로메테우스 의존성 추가
implementation 'org.springframework.boot:spring-boot-starter-actuator'
// Prometheus 전용 Micrometer 의존성 추가
implementation 'io.micrometer:micrometer-registry-prometheus'

- application.yml 설정에 따라 9512포트로 접속 테스트
- (*기본적으로 제공하는 페이지) = /actuator/health
application.yml 설정 추가 (프로메테우스 관련)
management:
endpoints:
web:
exposure:
include:
- health
- info
- metrics
- loggers
- threaddump
- prometheus # 추가
endpoint:
health:
show-details: ALWAYS
health:
db:
enabled: true
diskspace:
enabled: true
info:
env:
enabled: true
info:
app:
name: "My Spring Boot Application"
version: "1.0.0"
team: "My Dev Team"- management...include:
웹을 통해 접근 가능한 Actuator 엔드포인트를 지정
나열된 엔드포인트만 http://localhost:9512/actuator/{엔드포인트이름} 형식으로 접근 가능
엔드포인트 종류 :
- health: 애플리케이션의 상태 정보 (ex. UP, DOWN 등)
- info: 애플리케이션의 일반적인 정보
- metrics: 애플리케이션의 다양한 메트릭 정보 (JVM 메모리 사용량, HTTP 요청 수, 데이터베이스 연결 상태 등)
- loggers: 애플리케이션에서 사용되는 로거 관련 정보
- threaddump: 애플리케이션의 스레드 덤프 정보를 제공 - management...show-details: ALWAYS:
상태 정보의 상세 내용을 항상 표시하도록 설정
기본적으로는 인증되지 않은 요청에는 간단한 상태 (UP 또는 DOWN)만 표시하고, 인증된 요청에만 상세 정보를 표시
ALWAYS 설정 : 인증 여부와 관계없이 항상 상세 정보를 확인 가능 - management.health.db.enabled: true:
➡️데이터베이스 연결 상태를 확인하는 헬스 체크를 활성화
애플리케이션이 데이터베이스에 정상적으로 연결되어 있는지 여부를 확인 - management.health.diskspace.enabled: true:
➡️디스크 공간 부족 여부를 확인하는 헬스 체크를 활성화
서버의 디스크 여유 공간이 특정 임계값 이하로 떨어지면 /actuator/health 엔드포인트에서 상태를 DOWN으로 표시
❓자주 쓰는 Actuator Endpoint
- /actuator/health ➡️서버가 정상 동작(UP) 중인지 확인 로드 밸런서나 헬스체크 툴에서 주로 사용
- /actuator/info ➡️ Git 커밋 정보, 빌드 버전, 팀 정보 등 다양한 메타 데이터 노출 info.* 설정을 통해 추가 가능
- /actuator/metrics ➡️ JVM Heap, GC, CPU 사용량, HTTP 요청 횟수, Database 쿼리 카운트 등 모니터 링Prometheus/Grafana 등과 연동하는 경우 /actuator/prometheus endpoint도 많이 사용
- /actuator/threaddump ➡️ 서버 내부 쓰레드 덤프 확인 장애 상황이나 무한 루프, Deadlock 분석에 유용
▶️실습 - SpringBoot + 프로메테우스 + 그라파나
- Docker 환경에서 실행 중인 Spring Boot 애플리케이션의 내부 메트릭을 Prometheus가 수집하고,
Grafana에서 시각화하는 일련의 과정 - Prometheus 세팅
- prometheus.yml 설정 파일 작성
- Prometheus 컨테이너로 실행
- Spring Boot에서 노출된 메트릭을 스크랩(scrape) - Grafana 세팅
Prometheus를 Data Source로 추가 → 대시보드 생성 → 실시간 모니터링 화면 구성
prometheus/prometheus.yml
global:
scrape_interval: 5s # 5초마다 스크랩
scrape_configs:
- job_name: "springapp"
metrics_path: "/actuator/prometheus"
static_configs:
- targets: ["api1:8080"]
- 5초마다 스크랩하는 설정과 job_name을 적절히 설정
프로메테우스 도커 실행
docker run -d ^
--name prometheus ^
--network spring-net ^
-p 9110:9090 ^
-v %cd%\\prometheus.yml:/etc/prometheus/prometheus.yml ^
prom/prometheus
- 9090은 이미 사용중이므로 다른 것 지정 → 9110
- prometheus 경로의 prometheus.yml 파일을 사용하겠다는 것을 윈도우에서는 cd 명령으로 접근하여 docker를 실행

- localhost:9110 으로 접속 테스트
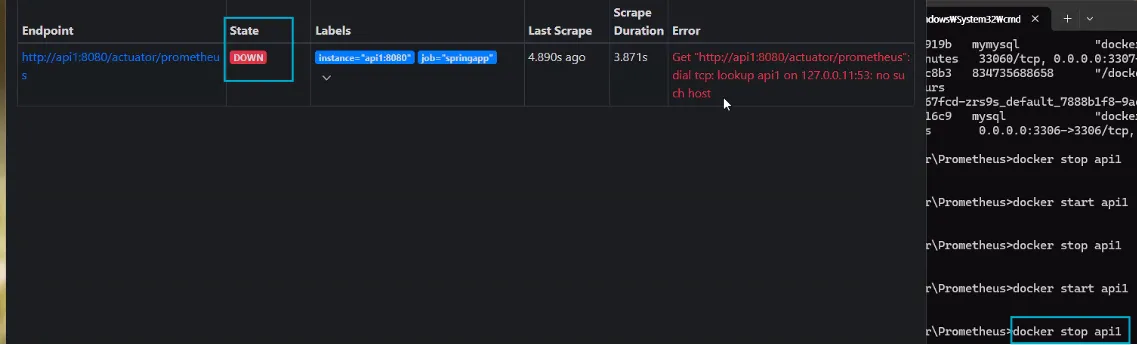
- docker stop api1 을 테스트해보면 state가 down된 상태로 되는 것을 확인할 수 있다.
- 프로메테우스는 설정에서 5초마다 스크랩하는것으로 되어있으므로
docker stop api1를 내리자마자 새로고침으로 확인해도 바로 적용 되지 않고
5초 후에 적용이 되는 것을 확인할 수 있다. - 프로메테우스는 즉 push를 하는 것이 아닌 pull을 해오는 것이라 볼 수 있다.

- 그래프를 확인해보았을때 프로젝트에 요청이 들어오면 이처럼 시각적으로 확인이 가능하다.
Grafana - 그라파나
Grafana 컨테이너 실행
docker run -d --name grafana --network spring-net -p 3000:3000 grafana/grafana-oss


- localhost:3000 에 접속하면 이처럼 로그인 페이지가 출력 (기본은 admin / admin)
Grafana - Dashboard
- Dashboards→ import → 링크 선택 → 검색 (spring) → 첫번째 JVM 선택 → COPY ID
- 기존 페이지에서 ID 붙여넣기 후 LOAD → 가장 밑 프로메테우스로 선택 후 IMPORT 클릭

- 데이터를 확인 가능
- Uptime : 애플리케이션(JVM)이 시작된 뒤 경과한 시간
일반적으로 애플리케이션이 정상적으로 동작 중인지, 재시작이 있었는지 등을 파악하는 데 사용 - Start time: 애플리케이션이 기동(Startup)된 시각
- Heap used : JVM Heap 메모리가 현재 어느 정도 사용되고 있는지를 %로 표현한 값
Java 객체가 실제로 차지하는 Heap 영역을 측정
Heap 메모리가 계속 치솟으면 GC(가비지 컬렉션) 동작을 확인하거나 메모리 누수를 의심 - Non-Heap used : JVM Non-Heap 영역 사용 비율
Heap 영역 이외에 클래스 정보, Metaspace, Thread stack 등이 포함

- 이처럼 Code부분에 쿼리를 넣어주면 변화하는 그래프를 확인할 수도 있다.
쿠버네티스 Kubernetes (=k8s)
- 컨테이너 (도커 등)을 대규모로 배포하고 운영하는 ⭐“오케스트레이션 플랫폼”
- 여러 대의 서버(노드) 위에서 컨테이너 애플리케이션을 자동으로 배포, 확장, 복구, 로드밸런싱해주는 기능 제공
- 도커 : 개별적인 애플리케이션과 그 의존성들을 격리된 환경인 컨테이너로 패키징하고 실행하는 기술로
마치 하나의 독립된 작은 방에 필요한 모든 것을 담아두고 실행하는 느낌
ex. 각 트럭(컨테이너)은 특정 물건(애플리케이션)을 싣고 목적지까지 운반
도커는 각 트럭을 만들고 운전하는 방법을 제공 - 쿠버네티스 (Kubernetes): 컨테이너 오케스트레이션 시스템
여러 개의 도커 컨테이너를 효율적으로 배포, 관리, 확장하는 것을 자동화하는 플랫폼
마치 여러 척의 택배 트럭을 중앙에서 지휘하고 관리하여 전체 물류 시스템을 최적화하는 "본사" 느낌
ex. 여러 대의 택배 트럭을 관리하는 중앙 물류 센터
쿠버네티스는 어떤 트럭이 어떤 물건을 어디로 배송해야 하는지 결정 및 트럭 고장 시 새 트럭 투입 등을 수행
❓쿠버네티스를 사용하는 이유
높은 가용성 (High Availability)과 탄력적인 확장성 (Scalability)을 확보하기 위함
ex. 구글과 같은 대규모 서비스를 운영하는 회사에서는 단일 서버의 장애가 전체 서비스 중단으로 이어질 수 있기 때문에, 쿠버네티스와 같은 컨테이너 오케스트레이션 시스템이 필수적
높은 가용성 (High Availability)
➡️장애 복구 (Self-healing): 쿠버네티스는 컨테이너나 노드(서버)에 문제가 발생했을 때 자동으로 감지하고 복구
➡️분산 아키텍처: 애플리케이션의 여러 인스턴스를 여러 서버에 분산시켜 운영하여 단일 서버 장애 영향을 줄임
쿠버네티스의 주요 컴포넌트
- Control Plane(마스터 노드)
- API Server: 모든 쿠버네티스 명령과 요청을 받는 관문
- Scheduler: 새로 생성된 컨테이너(Pod)를 어떤 워커 노드에 배치할지 결정
- Controller Manager: 전체 시스템 상태를 원하는(정의된) 상태로 유지하도록 각 종 컨트롤러를 실행 - Worker Node(워커 노드)
- Kubelet: 컨테이너 런타임(Docker, Containerd 등)과 연동하며, Pod을 생성·삭제 ·모니터링
- Kube-Proxy: 네트워크 통신 담당. 외부 트래픽을 적절한 Pod으로 라우팅
쿠버네티스의 주요 리소스
- Pod: 컨테이너가 실제로 동작하는 최소 배포 단위(하나 이상의 컨테이너를 포 함)
- Deployment: 여러 Pod을 어떻게 배포하고 업데이트할지(롤링 업데이트, 스케 일링 등) 정의하는 상위 개념.
- Service: Pod을 묶어 네트워크 액세스(LoadBalancer, NodePort 등)를 제공
쿠버네티스 비유
- 쿠버네티스 (=본사, 마스터노드)
- 노드 (=택배상자들을 싣고 다니는 트럭)
- pod (=배송트럭에 들어있는 택배상자)
- 컨테이너 (=택배상자안에 들어있는 물건)
- Deployment (=본사에서 관리하는 배송 계획표)
kubectl
- 쿠버네티스 기본 오브젝트, (=쿠브씨티엘, 큐브컨트롤)
- 쿠버네티스 클러스터를 제어할 때 가장 많이 사용하는 CLI 도구

- version 확인 가능

- pod목록 확인 가능
🚀회고 결과 :
쿠버네티스에 대해 배워보고 싶었는데 이번 학습과 회고로 배울 수 있었다.
도커보다 큰 개념임을 알 수 있었고 컨테이너를 관리하는 모니터링 도구. 프로메테우스와 그라파나 등에 대해서도 어원을 찾아볼 수 있었던 회고 시간이었다.
향후 계획 :
- 쿠버네티스 명령어 실습
'Recording > 멋쟁이사자처럼 BE 13기' 카테고리의 다른 글
| [멋쟁이사자처럼 부트캠프 TIL 회고] BE 13기_77일차_"빌드 자동화" (0) | 2025.04.01 |
|---|---|
| [멋쟁이사자처럼 부트캠프 TIL 회고] BE 13기_76일차_"쿠버네티스 Kubernetes" (0) | 2025.03.28 |
| [멋쟁이사자처럼 부트캠프 TIL 회고] BE 13기_74일차_"Docker 로드밸런싱" (0) | 2025.03.26 |
| [멋쟁이사자처럼 부트캠프 TIL 회고] BE 13기_73일차_"Docker 이미지" (1) | 2025.03.25 |
| [멋쟁이사자처럼 부트캠프 TIL 회고] BE 13기_72일차_"Docker 네트워크" (0) | 2025.03.24 |