
🦁멋쟁이사자처럼 백엔드 부트캠프 13기 🦁
TIL 회고 - [13]일차
🚀13일차 MySQL Workbench에서 실습을 진행하면서 다양한 단일행 함수, 그룹함수, 조인, 서브쿼리 등을 배울 수 있었다.
하루만에 많은 개념을 익혀야해서 회고를 정리를 통해 복습해야겠다고 느꼈다.
인덱스 Index
- 데이터를 빠르게 찾아내기 위해 "인덱스 사용"
- 고유값이 있으면 그것을 기준으로 트리를 만듦 (ex.작으면 왼쪽, 크면 오른쪽)
- 모든 데이터를 검색해서 찾는 것보다 이렇게 트리구조로 찾게되면 더 빨라질 수 있다.
- 검색 대상에 자주 검색하는 것(ex.컬럼)에 “인덱스”를 만들어두고,
인덱스가 걸려있는 컬럼으로 데이터를 찾게 되면 훨씬 더 빠르게 데이터를 찾아낼 수 있음
-- 이러한 방식으로 찾으면 시간이 오래걸릴 것
select * from employees where first_name = "Karen";
select * from employees where employee_id = 114;
- 이렇게 인덱스를 이용하여 찾는 것이 훨씬 더 검색속도가 빠르다는 것
PRIMARY KEY 기본 키

- 유일한 값이 PRIMARY KEY이며 (=키 값) “중복될 수 없는 값” (ex. 주민등록번호, 학번)
- 키 값을 가지고 있어야 데이터값이 중복이 되지 않아
데이터베이스가 가져야하는 성질 중 “무결성” 등을 충족할 수 있다. (무결성 중 정확성 : 데이터가 중복되지 않음) - 유니크한 값들은 테이블을 생성할때 자동으로 인덱스를 “설정”해주게됨
- 임의로 인덱스를 설정할 수도 있음.
하지만 값이 변경될때마다 인덱스 또한 값을 변경해주어야하기때문에 무분별한 인덱스 설정은 좋지 않음

- show index : 인덱스를 가진 것들을 출력
- 인덱스는 값의 분포도가 넓은 것에 유리
- 인덱스의 안좋은 예) → 성별 - 남/여 (값이 2개인 경우) 속도에 이점을 볼 수 없음
- 인덱스의 좋은 예) → 주민등록번호, 학번, 사원번호 등
👀데이터베이스 튜닝 :
전문가가 데이터베이스 안을 검색해서 적절한 컬럼에 인덱스를 거는 방법 등으로 속도 개선
인덱스 생성

- create index 로 인덱스를 생성한다.
인덱스 삭제
drop index index_employees_first_name on employees(first_name);
- drop index 로 인덱스를 삭제한다.
문자형 함수
LPAD / RPAD
-- lpad() : lpad(문구, 총자릿수, 문구왼쪽에 채울 문자)
select lpad('hi', 5, '?'); -- ???hi 출력
- 함수임에도 타입이 맞지 않으면 에러가 날 수 있기때문에 cast()함수를 통해서
- sal (급여)를 char형으로 바꿔주고, 급여 왼쪽에 *로 채운 후 총 10자리를 출력하는 예제이다.
TRIM / LTRIM / RTRIM
- 중간에 있는 공백은 없애주지 않는다.

- 좌우 공백만 없애주는 것을 확인 가능
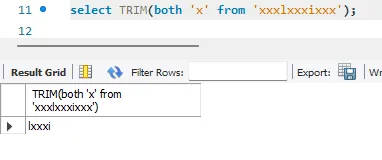
- 문자를 지정하여 좌우에 해당하는 그 문자를 지우는 것을 확인가능하고 > ???hi 출력
- 공백과 마찬가지로 중간의 x는 지워주지 않는다.
숫자형 함수
-- 숫자형 함수 ABS(x) : 절대값
select abs(2), abs(-2);
-- MOD(n, m) % : n을 m으로 나눈 나머지 값 (3가지 경우)
select mod(5, 2),5 % 2, mod(30, 4);
-- ceiling(x) : x보다 작지 않은 가장 작은 정수 반환
-- round(x) : x에 가장 근접한 정수 반환
select ceiling(1.23), round(1.23);
-- round(x, d) : x값 중 소수점 d자리에 가장 근접한 수로 반환
select round(1.298, 1); -- 1.3
-- pow(x,y) / power(x, y) : x의 y제곱 반환
select pow(2, 2), power(2, -2);
-- sign(x) : x=음수이면 -1, 0이면 0, 양수이면 1 출력
select sign(-1), sign(0), sign(300);
-- greatest(x, y, ...) : 가장 큰 값 반환
-- LEAST(x, y, ...) : 가장 작은 값 반환
select greatest(2, 0), greatest(4.0, 3.0, 5.0), greatest("B", "A", "C"),
least(2, 0), least(4.0, 3.0, 5.0), least("B","A", "C");- 절대값, 나머지, 반올림, 제곱, MIN/MAX값 반환 등 다양한 숫자형 함수를 실습해보았다.
날짜형 함수
-- 오늘 날짜 출력
select curdate(), current_date();
-- 현재 시각 출력
select curtime(), current_time();
-- 현재 시각 반환 (모두 같은 기능을 하는 함수)
select now(), sysdate(), current_timestamp();
-- date_format(date, format) : 입력된 date를 format형식으로 반환
select date_format(curdate(), '%W %M %Y'); -- 출력 : Wednesday december 2024- 자바와 마찬가지로 날짜와 시각, format을 사용하는 함수 등을 사용 가능하다.
▶️실습 - 근속 기간 구하기 (period_diff(p1, p2) 함수 활용)

형변환 함수
CAST()
- CAST() 혹은 CONVERT() 함수 사용 가능
cast(1-2 as unsigned);- 부호를 표현할 수 없는 정수 표현
- 값을 표현할 수 없으므로 오버플로우 발생
cast(-1 as unsigned), cast(-1 as signed);- 오버플로우가 발생하지 않고 -1이 잘 출력
그룹함수
- 이전까지 배운 단일행함수와는 달리
- 전체 행에 대해서 값을 “하나”구해내는 것을 확인할 수 있음
select sum(sal) from emp;
select avg(sal) from emp;

- 값이 전체 행에 대해 연산 후 "하나의 값"으로 조회가 됨을 확인가능
GROUP BY
- group by 컬럼 : 컬럼을 기준으로 그룹핑 (입사년도 별 사원 수 등)

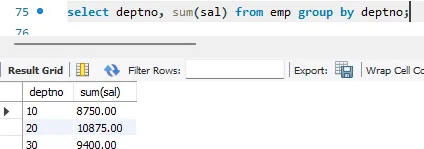
select deptno, sum(sal) from emp group by deptno;
- deptno 컬럼을 추가하여 그룹핑해놓은 컬럼을 명시적으로 출력
- 반드시 select절 뒤에 올 필요는 없지만 의미를 명확하게 하기 위해 기술
- ⭐그룹핑에 참여한 컬럼만 select로 지정할 수 있다.
▶️예제 - 그룹핑 오류 발생 가능
-- 그룹함수에 참여가능한 컬럼 -> 그룹핑에 참여한 컬럼만 select절에 올 수 있음
select ename, deptno, sum(sal) from emp group by deptno; -- (X) 오류 발생
select job, sum(sal) from emp group by job; -- (O) job에 해당하는 그룹이므로 정상실행- ename은 그룹핑에 참여하지 않았으므로 오류 발생
- job은 그룹핑에 참여했으므로 정상 실행

- 여러개의 그룹핑도 가능하며, 정렬은 문장 마지막에서 수행
COUNT
- (= Row 카운팅)
- COUNT(컬럼명)
- 주로 많이 쓰는 그룹함수 (ex.전체 사원이 몇명인지 알고싶거나, 개수를 세고 싶을때)
- NULL값은 포함하지 않는다.
그룹함수와 WHERE
select deptno, job, ave(sal) from emp where deptno = 20 group by job;
- 우선순위로 그룹핑부터 수행한다.

그룹함수와 HAVING
- having이 단독으로 쓰일 수도 있다.
- 그룹핑한 데이터들에 대한 조건을 부여하는 것이다.
- 위의 예제에서 연장하여 전체사원에서 그룹핑을 통해 걸러낸 데이터들 중
부서번호가 20번인 부서만 출력하고 싶을때는 having의 사용또한 고려해야한다.
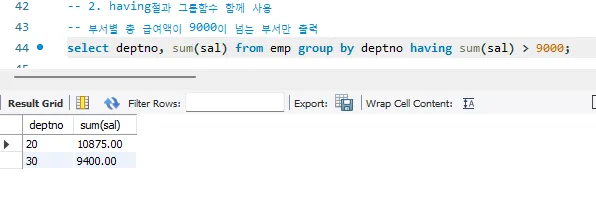
▶️예제 - 그룹함수와 where + having이 같이 쓰이는 경우
- 전체 데이터에서 제외할 것은 where으로 빼고
- 그룹핑을 한 다음에는 특정 조건의 부서만 보고 싶을때는 having으로 조건을 부여

- 부서별 평균 금액을 출력하는데, 평균급여가 2500보다 작은 부서만 출력한다.
- 대신 급여가 4500이상, 1000미만인 사람을 제외하고 그룹핑을 진행 평균급여를 구한다.

- 이처럼 ALIAS를 이용하여 avg(sal)이 자주 쓰이므로 “평균급여”로 별칭을 설정하여 자주 사용할 수 있다.
SELECT 구문의 전체 문형
select(distinct) 컬럼명(alias)
from 테이블명
where 조건식
group by 컬럼명
having 조건식
order by 컬럼이나 표현식 (asc or desc)
- group by : 전체 데이터를 소그룹으로 나누어 컬럼을 명시함
- where : 조건절로 group by 와 함께 쓰이면 전체 데이터 중에서 조건에 해당하는 것을 그룹핑
- having : group에 대한 조건을 기술. 그룹핑을 통해 걸러진 데이터들에 대한 조건을 명시
JOIN 조인
- 두 테이블이 접근하는 방법
- 테이블 하나에서 데이터를 꺼내지 않고 쪼개진 여러 개의 테이블에서 원하는 정보를 꺼내온다.
- from절 뒤에 하나의 테이블뿐만 아니라 여러 개의 테이블을 기술 가능
> 하지만 여러개의 테이블을 사용하다보면 원치 않는 데이터들이 조회되는 경우도 있다.
-- (잘못된 사례)
select empno, ename, dname, sal from emp, dept;

- 부서테이블이 4개가 있으면 사원 한 명당 그 부서테이블 4개를 참조하는 모든 경우의 수가 출력
- 모든 경우의 수가 출력되는 것은 불필요하므로 이럴때 조인 조건을 사용
- SMITH라는 사원의 부서번호를 알아내고 그 부서이름은 RESEARCH 인 것을 확인할 수 있음
- 따라서 이렇게 테이블을 여러개 참조하고 싶을때는 “조인 조건”을 알아야한다.
- ⭐조인을 하지 않으면 테이블 당 “행수를 곱한 것 만큼” 결과가 나오게되는데,
사용자는 모든 경우의 수를 보고 싶지 않기때문에 “조인을 사용한다”
JOIN 조인 사용법
-- (올바른 사례)
select empno, ename, dname, sal from emp, dept where emp.deptno = dept.deptno;
- .(온점)으로써 그 테이블을 참조한다는 것을 표시하고, 온점 이후로는 컬럼명을 참조한다.
- 조인을 할때 deptno 처럼 서로 같은 컬럼 값으로 조인을 하고있다. (조인 조건을 준 것)
-- 올바른 사례에서 부서번호 deptno를 select절에 위치시켜 오류가 발생한 예제
select empno, ename, deptno, dname, sal from emp, dept where emp.deptno = dept.deptno;- deptno는 “조인 테이블”이 생성되었을때 부서번호는 2개가 생기게 된다.
- emp테이블에도 deptno가 있고, dept테이블에도 deptno가 있는 것이다.
- 따라서 select절에서 deptno를 기술하게 되면 어떤 테이블에서 deptno를 출력할지를
컴퓨터가 스스로 판단하지 못하기때문에 오류가 발생하므로 명시 해야한다.
-- deptno를 명시한 예제
select empno, ename, emp.deptno, dname, sal from emp, dept where emp.deptno = dept.deptno;
- emp.deptno처럼 emp테이블의 deptno를 사용한다고 명시한다.

JOIN 조인하는 조건
- 다른 테이블의 기본키를 현재 테이블의 외래키로 참조할 수 있어야한다.
기본키 PRIMARY KEY
- 자신을 대표할 수 있는 키값
- ex. emp테이블은 empno가 [PRIMARY KEY] --- dept테이블은 deptno가 [PRIMARY KEY]
dept테이블을 확인해보면 deptno가 있고 (본인의 기본키)
emp테이블을 확인해보면 deptno가 있다. (다른 테이블을 참조하는 외래키) - emp테이블에서 dept테이블을 참조하기 위해서는 deptno라는 “외래키”를 이용하여
dept테이블의 기본키에 접근할 수 있는 것이다.
외래키 FOREIGN KEY
- null값이거나 다른 테이블과의 연관관계가 있는 값만 외래키로 지정할 수 있다.
- 외부에서 참조해온 키를 의미
조인을 통해 원하는 값에 접근하기

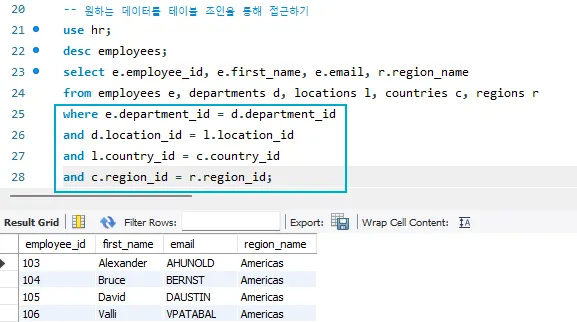
- 위의 그림에서 region_name에 접근하기 위해 EMPLOYEES 테이블에서 출발하는 경우
- 5개의 테이블을 이용해서 값을 꺼내오는 과정이므로, 조인 조건은 4개가 있다.
<원하는 값에 접근하는 과정> - ⭐1) EMPLOYEES의 department_id 외래키와 DEPARTMENTS의 department_id 기본키를 조인해서 접근
- 2) DEPARTMENTS의 location_id 외래키와 LOCATIONS의 location_id 기본키를 조인해서 접근
- 3) LOCATIONS의 country_id 외래키와 COUNTRIES의 country_id 기본키를 조인해서 접근
- 4) COUNTRIES의 region_id 외래키와 REGIONS의 region_id 기본키를 조인해서 접근
- 결국 EMPLOYEES 테이블에서 REGIONS 테이블의 region_id까지 조인을 통해서 접근할 수 있다.
조인의 종류
Cartesian Join 카테시안 조인
- = 크로스조인
- 조인 조건이 없는 조인
- 이러한 경우를 방지하기 위해 반드시 WHERE절을 사용
- (조인하는 테이블의수 - 1) 개의 조인 조건이 필요
Simple Join 심플조인
- 일반적으로 PK(PRIMARY KEY)와 FK(FOREIGN KEY)간 (=)조건이 붙는 경우가 많음
- 적절한 조인조건을 where절에 부여한 (테이블개수-1개의 조인조건)
- 테이블 이름에 alias 별칭을 사용하여 편히 접근가능
Equi-Join 이큐조인
- 가장 간단하게 많이 사용하는 것이 이큐조인
- 조인 조건이 Equal (=)인 경우 > 조건이 정확하게 “일치하는 경우”
- ex. EMPLOYEES테이블의 department_id와 DEPARTMENTS의 department_id가 같은 것을 가져옴
- 일반적으로 PK-FK 관계에 의해 JOIN이 성립
Inner Join 이너조인
- ex. 부서번호가 40번인 사원이 있으면 조인조건을 만족하는 “튜플만 나타남”
select e.ename, e.deptno, d.dname from emp e, dept d
where e.deptno = d.deptno;
- 조건을 만족하는 튜플만 나타남(이너 조인) + equal(=)연산자로 조인 조건을 찾음 (이큐 조인)
Outer Join 아우터조인
- ex. 부서번호가 40번인 사원이 있으면 조인조건을 만족하지 않는 튜플(=짝이없는 튜플)도 “null과 함께 나타남”
- Left Outer Join, Right Outer Join, Full Outer Join이 있는데
👀Full Outer Join은 MySQL에서 지원 X
Theta Join 세타조인
- FK, PK의 관계가 아닌 다른 정보를 가지고 사용해서 꺼내올 수 있는 조인
- 임의의 조건(theta)을 조인 조건으로 사용가능
- (=Non-Equi Join) 논 이큐조인

- between a and b : 더 작은 값이 앞에 와야함 ex. s_min_salary
Natural Join 자연조인
- from 테이블A natural join 테이블B
- Equi-Join, 동일한 Column명이 합쳐짐
- 두 테이블에 공통 컬럼이 있는 경우 별다른 조인 조건 없이 공통 컬럼처럼 묵시적으로 조인

Self Join 셀프조인
- 자기 자신과 조인 = 테이블 하나를 통해 조인
- ex. 테이블은 하나지만 EMPLOYEES테이블에는 사원과 매니저 정보가 들어있으므로
하나는 사원테이블, 하나는 매니저 테이블 이라고 “가정” - 사원 테이블을 보면 manager_id값을 가지고, manager_id는 사원번호이므로,
이 사번에 해당하는 사람이 그 사원의 매니저일것

- mgr은 scott데이터베이스에서 매니저 사원번호를 의미
- emp테이블의 매니저 사원번호와 매니저테이블의 일반 사원번호를 일치시켜 찾는다.
ANSI문법 - JOIN
-- 일반적인 조인 방법
use scott;
select e.ename, d.dname
from emp e, dept d
where e.deptno = d.deptno;
-- Natural Join 이름이 같은 컬럼이 두 테이블에 존재하면 그 컬럼을 기준으로 조인 조건을 만듦
-- (ANSI 문법) 1. natural join : 알아서 조인을 해줌
-- 단점 : 컬럼명이 중복될 수도 있다.
select e.ename, d.dname
from emp e natural join dept d;
-- 조인 using
-- (ANSI 문법) 2. join using : 컬럼지정을 하는 것 (이 컬럼을 가지고 조인을 하라는 명령)
select e.ename, d.dname
from emp e join dept d using(deptno);
-- 조인 on
-- (ANSI 문법) 3. join on : 컬럼에 대한 조건을 주는 것 (deptno가 같을때)
select e.ename, d.dname
from emp e join dept d on (e.deptno = d.deptno);
- 이 ANSI문법에는 join, natural join, using, on등을 사용할 수 있다.
- natural join의 단점을 해결하기 위해
using을 사용하게되면 컬럼명이 중복되어도 deptno로 명시하여 컬럼명 중복을 피할 수 있다.
▶️예제 - ANSI문법을 SELF JOIN에 적용한 예

서브쿼리 Subquery
- 하나의 SQL 질의문 속에 다른 SQL질의문이 포함되어있는 형태
- 하나의 쿼리(질문)로 답을 얻을 수 없는 경우에 사용

-
- 스미스 사원의 부서번호를 먼저 구하고 (외부 select)
- 내부에서 해당 사원의 평균급여를 구한다 (내부 select)
- 두 개의 쿼리를 한 문장으로 알아낼 수 있음
싱글 로우 서브쿼리 Single Row Subquery
- 서브쿼리의 결과가 한 ROW인경우 - 하나의 행인경우
- Single - Row Operator를 사용해야함 : =, >, ≥, <, ≤, <>
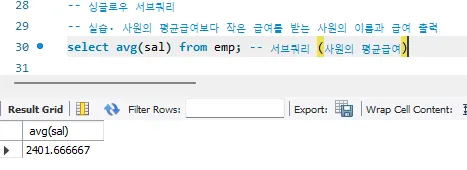
- 서브쿼리의 결과가 한 ROW로 출력됨
멀티 로우 쿼리 Multi Row query
- 서브쿼리가 한개가 아닌 여러 쿼리의 결과값을 가져올때는 =(equal)만으로는 비교가 안될 수 있으니
in, any, all과 같은 연산자를 결과를 조회할 수 있다. - ↔ 서브쿼리가 하나의 쿼리 결과값을 가져오면 = (equal) 만으로도 비교가 가능할 것. 이를 싱글로우 쿼리라고한다.
- IN 연산자와 밀접한 관련이 있음
IN 연산자
where ename in ("kang", "smith", "allen");
- ename이 kang이거나 smith이거나 allen이거나를 가져오는 경우
where ename = 'kang' or ename = 'smith' or ename = 'allen';
- 따라서 풀어서 설명하면 이와 같은 결과
- 💡in : (=or)의 조합이다.
- in연산자에서 하지 못하는 것을 any, all 을 통해 가능
- any = or 을 의미하고, all = and 을 의미
ANY 연산자
where ename in ("kang", "smith", "allen");
-- 는
where ename = any ("kang", "smith", "allen");
-- 와 같다.
- 이 중 하나라도 만족하면 true인것이 any
ALL 연산자
where sal > all (950, 3000, 1250);
-- 는
where sal > 950 and sal > 3000 and sal > 1250;
-- 와 같다.- 모두 만족해야 true인것이 all
select * from emp where sal > all (select avg(sal)
from emp
group by deptno);- 서브쿼리의 평균 급여보다 높은 급여를 출력
💡정리하자면
in은 equal(=) 사용
any는 equal(=), <, > 모두 사용가능하면서 or 의 조합
all은 equal(=), <, > 모두 사용가능하면서 and 의 조합
상호연관 쿼리 Correlated Query
- 전체 데이터의 쿼리가 실행될때, 한 row씩 검사해가며 실행됨
▶️실습 - 사원의 이름/급여/부서번호를 출력,
단 사원의 급여가 그 사원이 속한 부서의 평균급여보다 “큰” 경우만 출력
select * from emp;
-- 1. 외부 emp테이블이 갖고있는 deptno를 가지고 저 서브쿼리의 deptno를 알아낼 것
select ename, sal, deptno from emp;
-- where sal > (select avg(sal) from emp where deptno = ?);
-- 2. 수정한 쿼리
select ename, sal, deptno from emp o
where sal > (select avg(sal) from emp where deptno = o.deptno);- SMITH인 경우, 20번 부서번호의 평균급여를 실행해야한다.
- ALLEN인 경우에는 30번 부서번호의 평균급여를 실행해야한다.
- 이렇게 가변적인 값이 deptno인데 아직은 미지수인 값이다.
- 서브쿼리의 deptno와 외부쿼리의 o.deptno를 비교하여 해당하는 값을 찾는것이다.
- 쿼리문이 한 줄(한 row)씩 실행되는 것의 이점을 살린 경우이다.
정리하자면,
- 외부 쿼리의 한 row를 얻어낸다.
- 그 row를 가지고 서브쿼리를 계산한다. (내부쿼리계산)
- 계산결과를 이용하여 외부 쿼리의 where절을 검사한다.
- 외부 쿼리의 where절을 검사한 결과가 참이면 그 row를 결과에 포함시킨다.
서브쿼리로 테이블 만들기
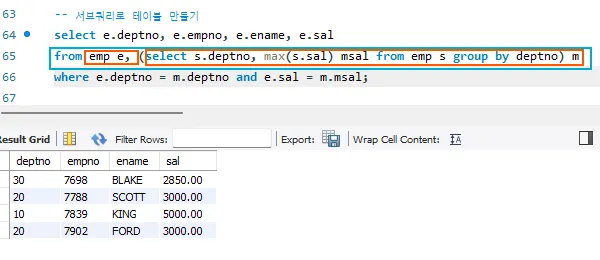
- from절 안에 서브쿼리를 두어 테이블을 만들어낼 수도 있다.
💡배운내용이 많아 회고를 정리하는데 시간이 오래 걸렸다. 덜어내는 연습을 하고자 했지만 중요해보이는 내용이
많아보여 나름의 정리를 하며 최대한 덜어내보았다.
회고록을 정리하면서 수업에서는 빠르게 지나갔던 내용이 다시 보이게 되고 개념들을 다시 이해하는데 큰 도움이 되었다!🚀
'Recording > 멋쟁이사자처럼 BE 13기' 카테고리의 다른 글
| [멋쟁이사자처럼 부트캠프 TIL 회고] BE 13기_15일차_''JDBC와 DAO/DTO" (2) | 2024.12.20 |
|---|---|
| [멋쟁이사자처럼 부트캠프 TIL 회고] BE 13기_14일차_'DML, DDL, TCL' (0) | 2024.12.19 |
| [멋쟁이사자처럼 부트캠프 TIL 회고] BE 13기_12일차_'MySQL+쿼리' (1) | 2024.12.17 |
| [멋쟁이사자처럼 부트캠프 TIL 회고] BE 13기_11일차_'데이터베이스' (1) | 2024.12.16 |
| [멋쟁이사자처럼 부트캠프 TIL 회고] BE 13기_10일차_'내부클래스와 제네릭' (2) | 2024.12.13 |