[멋쟁이사자처럼 부트캠프 TIL 회고] BE 13기_46일차_"JPA"
🦁멋쟁이사자처럼 백엔드 부트캠프 13기 🦁
TIL 회고 - [46]일차
🚀45일차 게시판 프로젝트 발표 이 후 46일차에는 Spring Data JPA를 배울 수 있었다.
JPA에 대해 자세히 알아보고 왜 활용되는지, 로그 처리와 더불어서 실습할 수 있었다.
학습 목표 : JPA에서 사용되는 기술들과 구성요소에 대해 익숙해지는 것
학습 과정 : 회고를 통해 작성
Spring Data JPA
- Spring Data JDBC와는 비슷하지만 내부적으로는 동작방식이 상이
- JPA (=Java Persistence API) : 자바 플랫폼에 대한 ORM 표준을 제공하는 API
- 객체 지향 모델을 관계형 데이터베이스의 테이블에 매핑하여
개발자가 DB작업을 더 직관적이고 객체 지향적인 방식으로 수행하도록 도움 - ORM = Object와 Relation을 매핑하는 과정
Persistence 영속성
- Data Layer = Persistence Layer = 데이터를 다루는 계층
- Persistence : 데이터를 유지할 수 있는 속성
- 구조 : Prestentation Layer - Service Layer - Data Layer(=Persistence Layer)에서 Data Layer에 속하는 것
EJB
- Enterprise Java Beans
- 큰 규모의 프로젝트를 만들때 사용했던 기술
- 장점 : 분산 처리
➡️서버 하나에서 동작하는 것이 아닌 서버 여러개에서 동작하도록 함
분산처리 : 높은 비용의 서버 하나보단 성능이 조금 낮은 낮은 비용의 여러 개 서버로 동작하는 개념 - 복잡한 여러 개의 서버 간 통신을 EJB기술로 구현
➡️EJB가 복잡한 분산처리를 도움
- 스프링을 사용하지 않고 자바 애플리케이션을 만들기 위해선 서블릿과같은 도구로 직접 생성하거나
Lombok 으로 @Getter, @Setter 를 포함하여 @Service, @Repository, @Component, @SpringBootApplication, @GetMapping 등 편하게 사용했던 기능들을 모두 직접 구현하여야함
JPA
- Java Persistence API
- DB작업을 추상화하여 특정 DB구현에 대한 의존성을 줄이고 , 개발자가 직접 SQL을 작성하는 복잡성을 감소시킴
- 엔티티라는 자바클래스를 DB테이블과 매핑하고, 이 엔티티 객체를 통해 데이터를 쿼리작성하거나 조작이 가능해짐
- 장점
➡️데이터 접근 코드 간소화개발자는 DB설계와 비즈니스 로직 구현에 더 집중 가능
➡️애플리케이션의 유지보수성, 확장성 향상
➡️DB 독립성 향상
JPA 등장 배경
- MyBatis(=마이바티스) : 쿼리문을 사용자가 짜주면 JDBC코드를 단축시켜서 사용할 수 있도록 함
- Hibernate(=하이버네이트) : 자바 객체와 관계형 DB의 관계를 알려주면 자동으로 채워질 수 있도록 함
Hibernate는 JPA API 인터페이스의 구현체로 이를 이용해 JDBC Driver를 이용하여 DB에 접속을 함 - 이러한 Hibernate에 대해 “표준을 제공할 목적으로” Java에서 개발한 것이 JPA
➡️즉 JPA는 Hibernate의 구현체부분을 꺼내서 표준을 정한 것 - JDBC를 간편하게 프레임워크로 구현한 것 = MyBatis, Hibernate, JPA
- ORM
➡️Entity(객체=Object)와 관계형 DB(=Relational)간의 관계를 알려주는 것
➡️Spring Data JDBC 에서 @Entity객체에 @Id, @Table을 알려주면 Repository 구현 시 자동으로 기능해주는 것 - JPA를 사용한다는 것은 Hibernate의 구현체를 사용하는 것
- JPA가 구현체를 가지고 있는 것이 아닌 Hibernate를 토대로 표준화된 JPA가 동작하는 것
➡️구현체가 바뀌어도 (=Hibernate가 바뀌어도) JPA 코드에서는 크게 변경할 일이 없을 것
JPA 주요 구성요소
- 엔티티 매니저 (Entity Manager)
➡️JPA를 통해 데이터베이스 작업을 수행하는데 중심역할을 하는 클래스 엔티티의 생명주기를 관리함
영속성 컨텍스트와 트랜잭션을 관리하고 있음 - 엔티티 (Entity)
➡️테이블에 담기는 객체를 의미
➡️데이터베이스의 테이블에 해당하는 클래스
JPA어노테이션을 사용하여 데이터베이스 테이블과 매핑됨
(=데이터베이스와 연결했을때 데이터 1건을 의미) - 영속성 컨텍스트 (Persistence Context)
➡️엔티티 인스턴스의 생명주기를 관리하는 환경 트랜잭션 범위 내에서 엔티티를 저장하고 관리
addEntity() : 실제 엔티티를 저장하는 역할을 수행 중 - 트랜잭션 (Transaction)
➡️DB작업을 묶어주는 방법으로 작업들이 모두 성공하거나 실패하게 보장
begin() - 시작, commit() - 커밋, rollback() - 롤백의 메소드를 가짐
영속성 구성파일
persistence.xml
<?xml version="1.0" encoding="UTF-8"?>
<persistence xmlns="http://java.sun.com/xml/ns/persistence"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://java.sun.com/xml/ns/persistence http://java.sun.com/xml/ns/persistence/persistence_2_0.xsd"
version="2.0">
<persistence-unit name="UserPU" transaction-type="RESOURCE_LOCAL">
<provider>org.hibernate.jpa.HibernatePersistenceProvider</provider>
<properties>
<property name="jakarta.persistence.jdbc.driver" value="com.mysql.cj.jdbc.Driver"/>
<property name="jakarta.persistence.jdbc.url" value="jdbc:mysql://localhost:3306/exampledb"/>
<property name="jakarta.persistence.jdbc.user" value="exam"/>
<property name="jakarta.persistence.jdbc.password" value="exam"/>
<property name="hibernate.dialect" value="org.hibernate.dialect.MySQLDialect"/>
<property name="hibernate.hbm2ddl.auto" value="update"/>
<property name="hibernate.show_sql" value="true"/>
<property name="hibernate.format_sql" value="true"/>
</properties>
</persistence-unit>
</persistence>- <persistence-unit>
➡️unit은 여러개 존재할 수 있음
➡️"UserPU" : unit의 이름은 임의로 지정 가능
➡️내부적으로 database를 가지고 있음 - Spring Data JDBC의 application.yml에서 datasource를 통해 데이터베이스의 접속정보를 가지고 있던 것처럼
persistence.xml에서도 DB 정보를 받아옴 - hibernate 설정
<property name="hibernate.dialect" value="org.hibernate.dialect.MySQLDialect"/>
<property name="hibernate.hbm2ddl.auto" value="update"/>
<property name="hibernate.show_sql" value="true"/>
<property name="hibernate.format_sql" value="true"/>- 실제 실행할 쿼리를 JPA가 만들어주는데 (실제로는 JPA 구현체가 만들어주는것으로 Hibernate가 만들어주는 것)
- SQL의 쿼리 규칙은 데이터베이스마다 조금씩 다른데
ex. MySQL에서 AUTO_INCREMENT를 사용하듯
Oracle에서는 Sequence객체를 이용 - hibernate.dialect
➡️Hibernate가 해당 DB가 가진 규칙에 따라 쿼리를 생성하는 것을 도움
따라서 dialect.MySQLDialect는 MySQL의 규칙에 맞춰 쿼리를 생성해준다는 의미 - hibernate.hbm2ddl.auto
➡️DDL (데이터 정의어)를 어떻게 할 것인지 설정
❓ddl-auto 속성
➡️create
JPA는 테이블도 생성해주는데 @Entity처럼 엔티티로 등록된 클래스와 매핑되는 테이블을 자동으로 생성(create)
만약 기존 클래스와 매핑되는 테이블이 이미 존재한다면 기존 테이블을 삭제(drop)하고 테이블을 생성
➡️create-drop
create와 유사하지만 애플리케이션이 종료될 때 테이블을 삭제하는 것이 차이점
➡️update
create와 동일하지만 기존 테이블이 존재한다면 create, create-drop과는 달리 테이블의 컬럼을 변경
➡️validate
다른 속성들과는 다르게 DDL을 작성하여 테이블을 생성하거나 수정하지 않고,
엔티티 클래스와 테이블이 정상적으로 매핑되는지만 검사
만약 테이블이 아예 존재하지 않거나, 테이블에 엔티티의 필드에 매핑되는 컬럼이 존재하지 않으면
예외를 발생시키면서 애플리케이션을 종료
➡️none
4가지 경우를 제외한 모든 경우에 해당
(다만 스프링부트의 경우에는 none이라고 명시하거나 아예 ddl-auto 속성을 명시하지 않아야 함
JPA API
- EntityManager
➡️이 인터페이스는 엔티티의 생명주기를 관리
CRUD작업을 통해 DB의 엔티티와 상호작용
➡️주요 메소드
persist(Object) - DB에 새 엔티티 저장
merge(Object) - 변경된 엔티티를 DB와 동기화
remove(Object) - DB에서 엔티티 삭제
find(Class, Object) - 주어진 ID로 DB에서 엔티티를 찾아 반환 - EntityTransaction
➡️이 인터페이스는 트랜잭션을 관리 >> 명시적으로 시작, 커밋, 롤백 ( begin(), commit(), rollback() )
중요성 : DB에 바로 쿼리가 적용되는 것이 아니라 트랜잭션이 종료될때 적용되도록 구현 가능 - EntityManagerFactory
EntityManager 인스턴스를 생성
애플리케이션에는 단 하나만 존재
User
@Table(name = "jpa_user")
@Getter
@Setter
@Entity
public class User {
@Id
private Long id;
private String name;
private String email;
public User(String name, String email) {
this.name = name;
this.email = email;
}
}
- @Table : jpa_user이름의 테이블을 만들어줌
- public User(String name, String email)
➡️Id를 제외한 생성자를 가지도록 만듦 - @NoArgsConstructor : 기본생성자 추가
- @Entity : 클래스에 엔티티로 정의하고 데이터베이스와 매핑될 수 있도록 만들어짐
UserRun
EntityManagerFactory entityManagerFactory = Persistence.createEntityManagerFactory("UserPU");
EntityManager entityManager = entityManagerFactory.createEntityManager();
System.out.println(entityManager);- JPA가 동작할때는 EntityManager가 필요
- 또한 EntityManager를 동작하기 위해서는 EntityManagerFactory가 필요
즉 EntityManagerFactory는 EntityManager를 만들기위한 것
- createEntityManagerFactory("UserPU");
persistence.xml에서 추가해주었던 persistence의 unit 이름인 UserPU와 일치해야함 - entityManagerFactory.createEntityManager();
EntityManager를 얻어낸다.
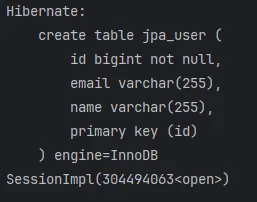
- create table jpa_user
실행 결과 : 테이블이 하나 만들어짐 - 다시 실행해보면 이미 테이블이 한 번 생성되었기때문에 create table jpa_user은 출력되지 않음

- 이유 : persistence.xml 설정파일에서 DDL 설정이 update로 설정되어있기때문에
기존 테이블이 존재한다고 가정했을때 update의 특징에 맞게 변경되는 컬럼이 없으므로
아무 출력이 발생하지 않는 것 - 만약 private String password; 처럼 필드 (=DB의 컬럼)을 추가해주고 실행해보면
alter table jpa_user { … } 출력 (테이블의 수정이 일어났다는 출력) - 만약 value=”create”로 바꾸면
기존 테이블은 drop하고 다시 생성하므로 create table jpa_user{…}는 실행때마다 출력
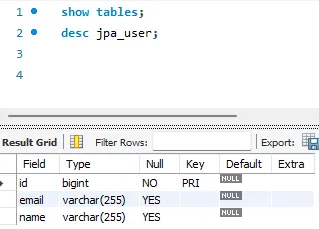
logback.xml
- resources → logback.xml 생성
<?xml version="1.0" encoding="UTF-8"?>
<configuration>
<appender name="STDOUT" class="ch.qos.logback.core.ConsoleAppender">
<encoder>
<pattern>%d{yyyy-MM-dd HH:mm:ss} [%thread] %-5level %logger{36} - %msg%n</pattern>
</encoder>
</appender>
<root level="debug">
<appender-ref ref="STDOUT" />
</root>
</configuration>- logback.xml : 출력 시의 형식을 정의
- ConsoleAppender : 콘솔에 출력할 것임을 의미
- <pattern> : 로그의 패턴(형식) 정의
영속성 적용방법
- 만약 UserRun 클래스에 엔티티를 새로 생성해볼때 영속성 컨텍스트가 관리하도록 하기위해선
// 엔티티
User user = new User();
user.setId(1L);
user.setName("sample");
user.setEmail("sample@exam.com");
// 엔티티가 생성 - 아직 영속성 컨텍스트와는 관계없는 상태 (비영속상태)
entityManager.persist(user); // 이 시점부터 user는 영속상태- entityManager.persist(user);
➡️이 시점부터 User타입의 user는 영속 상태로 변경 - persist() : 영속성을 주입하는 메소드
EntityTransaction (트랜잭션)
EntityTransaction transaction = entityManager.getTransaction();
transaction.begin();
// 엔티티
User user = new User();
user.setId(1L);
user.setName("sample");
user.setEmail("sample@exam.com");
// 엔티티가 생성 - 아직 영속성 컨텍스트와는 관계없는 상태 (비영속상태)
entityManager.persist(user);
System.out.println("트랜잭션.commit() 실행전");
transaction.commit();
System.out.println("트랜잭션.commit() 실행후");
- 실행해보면 "commit() 실행전"과 "commit() 실행후" 중간에 insert 쿼리가 수행됨
- 트랜잭션을 적용하지 않았으면 persist(user)로 영속성 주입을 하여도 아무런 쿼리 수행이 일어나지 않을 것
➡️트랜잭션으로 관리할 수 없었기 때문

JPA의 AUTO_INCREMENT
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
- 엔티티에 @GeneratedValue를 사용하여 MySQL의 AUTO_INCREMENT 구현이 가능
- @GeneratedValue : 값을 자동으로 넣어주는 어노테이션
- GenerationType.속성… : 다양한 자동생성기능을 제공
➡️AUTO : 자동으로 넣어줌
➡️IDENTITY : AUTO_INCREMENT 같은 MySQL의 기능을 구현해낼 수 있음
➡️SEQUENCE : 시퀀스 객체를 이용해서 번호를 받아서 Oracle의 기능을 구현해낼 수 있음
➡️TABLE : id테이블을 하나 만들어놓고 그 테이블을 통해 얻어서 사용하도록 함
➡️UUID : id값을 자동으로 생성해주는 기능
// 엔티티
User user = new User();
// user.setId(2L);
user.setName("sample");
user.setEmail("sample@exam.com");
- GenerationType을 적용하면 자동으로 id값을 증가시키면서 값을 넣게될 것

- 테이블을 새로 만들어 실습을 진행하면 create table jpa_user처럼 테이블 생성 쿼리가 수행됨
➡️id값은 auto_increment로 설정됨 (@GeneratedValue 적용 결과) - 만약 transaction.begin() 처럼 트랜잭션 시작을 명시하지 않으면 insert 쿼리문은 실행 되지 않을 것
➡️create table만 출력 (=DB에도 적용되지 않아 실제 값이 들어있지 않을 것)
➡️COMMIT이 될때에서야 DB에 쿼리의 수행결과가 담기기때문 - 정리하자면
실제 INSERT, DELETE 등의 쿼리 수행은 트랜잭션의 COMMIT이 수행되어야 실제로 일어남
⚠️다만 최초의 실행때는 테이블의 id값을 얻어오기위해서 트랜잭션의 시작을 명시하지 않아도
insert 쿼리가 실행될 수 있다.
(실제 입력을 위한 INSERT가 아닌 ID값을 구하기 위한 INSERT 이므로 실제로 DB에는 입력 되지 않음)
GenerationType.SEQUENCE
- MySQL은 SEQUENCE라는 객체가 없다. 따라서 id를 자동으로 증가해줄 수 있는 기능은 IDENTITY로 구현한다.
- Sequence객체를 이용하는 DB(ex. Oracle)의 경우 .SEQUENCE 속성을 사용하면
Hibernate:
create table jpa_user_SEQ (
next_val bigint
) engine=InnoDB
Hibernate:
insert into jpa_user_SEQ values ( 1 )
Hibernate:
select next_val as id_val
from jpa_user SEQ for update
Hibernate:
update jpa_user_SEQ
set next_val = ?
where next_val = ?- GenerationType.SEQUENCE 적용결과 이와 같은 출력
- next_val bigint : next_val 컬럼 하나 밖에 없음
- insert into jpa_user_SEQ values ( 1 ) : 초기값으로 1을 넣음
- 이처럼 sequence객체를 사용하는 DB의 경우 처음에 초기값과 증가값을 설정할 수 있다.
다시 실행해보면
Hibernate:
select next_val as id_val
from jpa_user SEQ for update
Hibernate:
update jpa_user_SEQ
set next_val = ?
where next_val = ?
- update 쿼리만 수행된다.
엔티티의 비영속상태 vs 영속상태
User user2 = new User("kim", "kim@exam.com");
User user3 = new User("kim2", "kim@exam.com");
User user4 = new User("kim3", "kim@exam.com");
- User엔티티를 여러 개 만듦 >> 비영속 상태
- 비영속 상태이므로 실행해보면 트랜잭션이 begin(), commit()까지 실행되고 있음에도
DB에는 실제 변화가 일어나지 않는다.
entityManager.persist(user2);
entityManager.persist(user3);
entityManager.persist(user4);
- 영속 상태로 추가해주어야 EntityManager가 관리하면서 EntityTransaction 에서도 관리할 수 있게 되는 것
JPA의 데이터 조회 - SELECT
// <<SELECT>> : 데이터 조회
User user = entityManager.find(User.class, 2L);
System.out.println(user);
System.out.println("트랜잭션.commit() 실행전");
transaction.commit();
System.out.println("트랜잭션.commit() 실행후" );- entityManager.find(User.class, 2L)
➡️find()를 이용해 id값으로 찾아서 user 객체에 담음
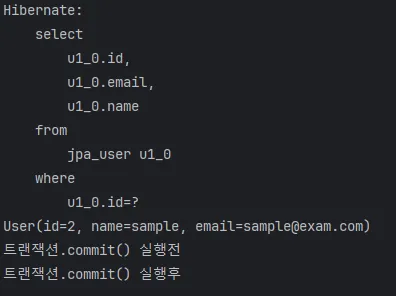
// <<SELECT>> : 데이터 조회
User user = entityManager.find(User.class, 2L);
User user2 = entityManager.find(User.class, 2L);
if(user == user2){
System.out.println("user == user2 >> user와 user2는 같은 객체입니다.");
}else{
System.out.println("user != user2 >> user와 user2는 다른 객체입니다.");
}
- 만약 똑같은 id의 엔티티를 find()로 찾아서 각각 user, user2 객체에 넣어준다면

- 같은 객체라고 출력됨
❓같은 객체로 출력되는 이유
➡️find()는 DB에 가서 검사하지 않고 1차적으로 영속성 컨텍스트에 이러한 ID가 있는지 검사하기때문이다.
영속성 컨텍스트에서 관리하고 있는 엔티티가 존재하면 find()를 통해 엔티티를 바로 반환하기때문에
만약 똑같은 ID로 find()를 수행하면 1차적으로 영속성 컨텍스트에 물어보는 것이므로 같은 엔티티를 반환하게 된다.
JPA의 데이터 수정 - UPDATE
// <<UPDATE>> : 데이터 수정
user.setName("new_sample");
System.out.println("트랜잭션.commit() 실행전");
transaction.commit(); // 영속성 컨텍스트를 분석해서 알맞는 동작을 수행
System.out.println("트랜잭션.commit() 실행후" );
- commit() 메소드는 영속성 컨텍스트를 분석해서 알맞는 동작을 하게되는 것
- JPA의 UPDATE 동작 과정
1. 처음 “SELECT - 조회” 할때 find() 메소드 호출
2. find() 메소드로 반환된 값(id = 2L, name = sample)을 “스냅샷”을 찍어 저장해놓음
3. 이 후 commit() 시 find()에서의 저장했던 스냅샷의 값과 엔티티에 저장된 값을 비교하여 update()를 수행
➡️만약 스냅샷이 없으면 DB에 처음 값을 넣는 것이므로 INSERT문을 수행
JPA의 데이터 수정 - UPDATE에서의 스냅샷 - Snapshot
User user = entityManager.find(User.class, 1L);
user.setName("newSample"); // DB에 바로 접근해서 수행하지 않음
// = 트랜잭션이 종료될때까지는 영속성 컨텍스트에서 관리하는 것
// 중간에 다른 일 수행
User user2 = entityManager.find(User.class, 1L);
user2.setName("sample");
- 스냅샷 동작 과정
1. 처음 find() 메소드 호출
2. find() 메소드로 반환된 값(name = sample)을 스냅샷을 찍어놓음
3. 이 후 user.setName("newSample")을 통해 name을 바꿈
4. 다시 user2 객체에서 user2.setName("sample")을 통해 name을 기존 name으로 바꿈
5. 영속성 컨텍스트에서 관리하고 있는 엔티티는 기존의 (sample) name을 가지고 있으므로
6. 엔티티 값에 변화가 없는 것으로 판단하여 commit()이 되어도 불필요한 업데이트를 수행하지 않음

- 즉 select만 한번 실행할 뿐 아무일도 일어나지않음
➡️트랜잭션이 종료될때까지는 영속성 컨텍스트에서만 관리한다는 것 (DB에 실제 수행되지 않음)
➡️트랜잭션이 종료되어야 영속성 컨텍스트를 분석해서 (DB에 실제 수행) - 스냅샷을 찍어놓는 것 = “1차 캐시”
➡️JPA는 1차캐시를 통해 DB에 실제 수행하는 불필요하는 작업은 수행하지 않고
실제 일어나야하는 작업들만 수행하게됨
불필요한 작업을 판단하는 것은 “영속성 컨텍스트”가 판단 - 대체로 업무 하나에 트랜잭션 하나로 트랜잭션이 많은 작업을 수행하지 않음
- 스냅샷 사용으로 극적인 성능변화를 기대하기 어렵지만 성능이 개선될 순 있음
➡️매번 find()하는 것이 아닌 영속성 컨텍스트가 가지고 있는 것들을 먼저 물어보고
영속성 컨텍스트에 없을때만 DB에 접근하기때문이다.
JPA의 데이터 삭제 - DELETE
// <<DELETE>> : 데이터 삭제
User user5 = entityManager.find(User.class, 1L);
entityManager.remove(user5);
System.out.println("트랜잭션.commit() 실행전");
transaction.commit(); // 영속성 컨텍스트를 분석해서 알맞는 동작을 수행
System.out.println("트랜잭션.commit() 실행후" );


- commit()이 되어야 실제 remove()가 수행
- 실제 DB에도 id=1 데이터가 삭제된 것을 확인 가능
JPA의 CRUD 연산을 DAO로 관리
UserDAO
public class UserDAO {
private EntityManagerFactory entityManagerFactory;
public UserDAO() {
entityManagerFactory = Persistence.createEntityManagerFactory("UserPU");
}
}
UserDAO - 생성 메소드 추가
// User엔티티를 받아서 생성
public void createUser(User user){
EntityManager entityManager = entityManagerFactory.createEntityManager();
try{
entityManager.getTransaction().begin();
// 엔티티를 영속성 컨텍스트에서 관리할 수 있도록 받아들인 user엔티티를 넣음
entityManager.persist(user);
entityManager.getTransaction().commit();
}finally{
entityManager.close();
}
}
UserDAO - 조회 메소드 추가
// 데이터 조회 메소드
public User findUser(Long id){
EntityManager entityManager = entityManagerFactory.createEntityManager();
try{
// find()는 트랜잭션 안에 들어가있지 않아도 동작하므로
return entityManager.find(User.class, id);
}finally{
entityManager.close();
}
}
UserDAO - 수정 메소드 추가
// 데이터 수정 메소드
public void updateUser(User user){
EntityManager entityManager = entityManagerFactory.createEntityManager();
try{
entityManager.getTransaction().begin();
entityManager.merge(user);
entityManager.getTransaction().commit();
}finally{
entityManager.close();
}
}UserDAO - 삭제 메소드 추가
// 데이터 삭제 메소드
public void deleteUser(User user){
EntityManager entityManager = entityManagerFactory.createEntityManager();
try{
entityManager.getTransaction().begin();
entityManager.remove(entityManager.contains(user)?user : entityManager.merge(user));
entityManager.getTransaction().commit();
}finally{
entityManager.close();
}
}- ⚠️기존 코드 : entityManager.remove(user);
➡️오류 발생 : 영속성 컨텍스트가 각 메소드마다 서로 다르기때문 (=트랜잭션이 각 메소드마다 서로 다르기때문) - ✅해결방법 - 삼항연산자 활용
User user를 받아왔을때
➡️user가 존재한다면 user를 바로 remove()에 넘겨 엔티티를 제거
즉 이 경우 user가 Managed 상태(영속 상태)인지 체크하는 것
➡️user가 존재하지 않는다면 merge(user)를 통해 병합한 후 remove()에 넘겨 엔티티를 제거
즉 이 경우 user가 Detached 상태(영속 컨텍스트에 존재하지 않는 상태)인 것 - 정리하자면 현재 영속성 컨텍스트안에 해당 엔티티가
이미 존재한다면 remove하고 없다면, merge후 remove - 즉 EntityManager가 만들어진다는 것은 영속성 컨텍스트가 만들어진다는 것이고,
영속성 컨텍스트 하나 당 하나의 트랜잭션을 관리한다는 것
로그 Log
- @Slf4j 어노테이션을 붙여서 사용하거나, 직접 final로 정의해서 사용 가능
- 로그의 레벨이 존재함 : ex. 기본정보 출력, 에러 발생 출력 등
- info() : 기본정보 출력 >> println()와는 다른 방식
- 로그를 사용하여 로깅처리하는 것(=로깅) : 디버깅, 모니터링 및 오류 추적에 필수적
다양한 로깅 프레임워크에 대한 일관된 인터페이스 제공, 개발자가 로깅 구현체를 쉽게 교체할 수 있도록 도와줌 - Log를 남기기위해서 주로 로깅 라이브러리들이 표준화되어있는 형태인 SLF4j를 사용
데이터 조회 - 로그를 적용하지 않았을때
public static void main(String[] args) {
UserDAO userDAO = new UserDAO();
// 데이터 조회
User user = userDAO.findUser(2L);
System.out.println(user);
}
1번방법. @Slf4j 어노테이션 로그 사용법
@Slf4j
public class UserMain {
public static void main(String[] args) {
UserDAO userDAO = new UserDAO();
// 데이터 조회
User user = userDAO.findUser(2L);
System.out.println(user);
log.info("=====[문자열 log]=====");
log.info("[문자열 + 객체] - find user : {}", user);
log.info("[문자열 + 객체] - find user : {}{}", user.getName(), user.getEmail());
// 이처럼 {}에 값들을 매핑시킬 수 있다.
}
}

2번방법. Logger 사용법
public class UserMain {
private static final Logger log = LoggerFactory.getLogger(UserMain.class);
public static void main(String[] args) { ... }
}- Logger 객체를 LoggerFactory로 불러와서 사용 가능
이처럼 Lombok을 이용한 @Slf4j 방법과 Logger 를 사용한 방법이 있다.
❓System.out.println() 과 Log 사용의 차이점
System.out.println()은 System을 직접 접근하는 코드이므로 프로젝트 관리 시 성능 저하가 발생할 수 있음
Log 사용은 System.out.println()사용보다 권장되는 방법임
System.out.println()에 출력하는 것들을 대체하여 log.info()레벨에 출력할 수 있음
로깅 라이브러리
- SLF4J : JUL, Log4j, Logback 등의 로깅라이브러리를 사용할때의 표준화된 방식을 제공할 수 있도록 추상 레이어를 제공
따라서 SLF4J를 사용하는 것이 추후 다른 로깅 라이브러리로 구현체를 변경하여도 코드의 유지보수가 쉬울 것이다. - Logback : 성능도 좋고, 유연하게 만들어졌으므로 많이 사용되는 기술

- logback 사용 시의 로그 설정 파일 예시
- 만약 log4j.xml 로 바꾸면 Log4j2 로그 방식을 사용하게되는 것
로그 레벨
- TRACE
➡️가장 상세한 로그 레벨로 애플리케이션 실행흐름/디버깅 정보 를 상세히 기록, 주로 디버깅 시에 사용
- 개발이 진행될때는 TRACE, DEBUG등을 사용
- 실제 프로젝트가 운영될때는 ERROR, FATAL 정도 레벨의 이상만 찍히도록 로그 레벨을 변경해주어야함 - DEBUG : 디버깅 목적으로 사용, 개발단계에서의 상세한 정보를 기록
- INFO : 정보성 메시지를 기록, 주요 이벤트나 실행상태에 대한 정보 전달
- WARN : 경고성 메시지 기록, 예상치 못한 문제나 잠재적 오류 발생 상황을 알림
- ERROR : 오류 메시지를 기록, 심각한 문제 또는 예외상황을 나타냄
- FATAL : 가장 심각한 오류 메시지를 기록 , 일반적으로 이러한 오류는 복구가 불가능
- 로그레벨 변경법

- logback.xml 설정파일에서 level부분에 설정해줄 수 있다.
- 로그레벨은 application.properties나 application.yml 등에서도 간단히 설정해줄 수 있다.
- 로그 출력 지점 변경법

- logback.xml에서 <appender> 부분의 설정을 변경해준다.
- 여러 개의 appender를 지정할 수 있음
- ConsoleAppender로 설정되어있으면 콘솔창에 로그가 출력되는 형태
만약 File로 지정하면 File에 로그가 저장되도록 할 수 있고,
DB로 지정하면 데이터베이스에 로그가 저장되도록 할 수 있음
로깅의 중요성
- 스프링 부트는 로깅 작업을 간소화하고 자동화하여 개발자가 비즈니스 로직 구현에 더 집중할 수 있음
스프링부트에서는 logback-spring.xml 등의 설정파일로 로깅에 대한 구성파일을 쉽게 관리할 수 있음
DAO - UPDATE, DELETE
엔티티비교
// 엔티티 비교
User user2 = userDAO.findUser(2L);
boolean equalsResult = (user == user2);
log.info("[user == user2] : {}", equalsResult);

- ❓결과가 false인 이유
➡️각 메소드마다 EntityManager와 그 EntityManager에 맞는 Persistence Context가 만들어지기때문에
그에 따른 트랜잭션도 begin(), commit()이 따로 관리되고 있다.
따라서 처음 find()로 체크할때 영속성 컨텍스트에서 값이 존재하는지를 비교함
>> user와 user2는 다른 영속성 컨텍스트를 가지므로 실제 DB에 바로 접근해서 비교하게 된다.
➡️결국 다른 값으로 판단하고 false를 출력하는 것 (=트랜잭션이 달라졌기때문)
데이터 수정
// 데이터 수정
user2.setName("Rush");
userDAO.updateUser(user2); // user2의 이름을 변경 후 update를 수행해봄

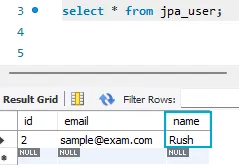
// 데이터 수정 - 2
User updateUser= new User("updateUser", "upt@test.com");
updateUser.setId(3L);
userDAO.updateUser(updateUser);
// 데이터 수정 - 3
User updateUser2= userDao.findUser(3L);
updateUser2.setName("newUser");
userDAO.updateUser(updateUser2);
- 이렇게 3가지 방법으로 테스트해볼 수 있다.
데이터 삭제
// 데이터 삭제 - id로 접근
User delUser = userDAO.findUser(4L);
userDAO.deleteUser(delUser);
- id=4에 해당하는 Antonee가 삭제되어야한다.
- deleteUser(delUser) 수행 전


- deleteUser(delUser) 수행 후

🚀로그 오류 해결
<encoder>
<pattern>%d{yyyy-MM-dd HH:mm:ss} [%thread] %-5level %logger{36} - %msg%n</pattern>
</encoder>
현재 log.info()등을 사용 시 <pattern>으로 로그 형식을 지정해놨지만 적용이 되지 않는 상태


- build.gradle의 slf4j 형식을 기반으로 [main] INFO org.example.jpa.UserMain 처럼 출력되는 것
✅의존성 변경 후 build.gradle 업데이트 (slf4j > logback)
// implementation 'org.slf4j:slf4j-simple:2.0.13'
implementation 'ch.qos.logback:logback-classic:1.2.11'
🚀회고 결과 :
이번 회고에서는 JPA와 로그처리를 배웠는데 특히나 로그 처리를 배운 것이 많은 배움이 된 것 같다.
System.out.println()처럼 테스트 시 사용하는 것을 어떻게 하면 관리할 수 있을까라는 생각을 했었는데
JUnit처럼 단위테스트를 사용하는 방법 등에 대해서는 얕게 알았어도 로그 사용방법은 잘 몰랐기때문이다.
- Slf4j 로그 용어에 대해 알게됨
- <pattern>으로 로그의 형식을 정의
- JPA에서의 트랜잭션
- commit()의 중요성
- 로그 레벨에 따른 로그 관리
- 영속성
- @GeneratedValue
느낀 점 :
이전 프로젝트를 진행하면서 JPA라는 기술도 있다는 것을 알게되었는데 오늘 접해보니
확실히 편리한 기능을 많이 제공하고 있었다. 로그 처리와 함께 JPA를 배우면서 JPA API에 대해 자세히 알 수 있었다.
향후 계획 :
- 다른 로깅 라이브러리에 대한 공부
- 로깅처리의 다양한 장점
- 영속성 구성파일 공부